
Leistungsfähige und hochflexible Cloudplattformen als Rückgrat des Informationszeitalters
Seit dem Ausgang des 20. Jahrhunderts leben wir in einer digitalen Gesellschaft. Wir gestalten gegenwärtig eine durch Digitaltechnik und Computer geprägte Lebensweise, die Historiker schon heute als die Epoche der „Digitalen Revolution“ bezeichnen.
Rückgrat der digitalen Anwendungen und Prozesse, die wir über optisch ansprechende Schnittstellen wie Web-Seiten, Smart TV‘s und Smartphone Apps nutzen, sind leistungsfähige und hochflexible Cloud-Plattformen. Diese Cloud-Plattformen stellen die erforderlichen Backend-Services bereit, die zum Betrieb der bunt schillernden grafischen Anwenderschnittstellen notwendig sind. Doch wie sieht die Welt hinter den Anwendungsschnittstellen aus? Was ist „Cloud“ und wie funktionieren diese Cloudplattformen, die in Publikationen von Hochglanzmagazinen als das ultimatives „Must-have“ des digitalen Daseins moderner, innovativer und zukunftsorientierter Unternehmen gepriesen werden?
Welche Mehrwerte versprechen Cloud-Plattformen?
In der „Cloud“ sind alle, in die „Cloud“ gehen alle (oder werden über mannigfaltige Wege mitgezogen), denn die „Cloud“ verspricht diese Vorteile:
- einen schonenden Umgang mit dem IT-Budget
- hohe Sicherheit
- super flexible Prozesse
- eine schnelle digitale Präsenz beim Kunden
Kurzum, günstige und stressfreie „Computing-Power aus der Steckdose“ für alle IT-Aufgaben, ... und für die komplexeren gibt es dort auch KI (Künstliche Intelligenz).
Whitepaper DevOps und Cloud
Sie wollen die Basis effizienter Automatisierung schaffen? Erfahren Sie in unserem Whitepaper, warum DevOps und Cloud mehr zusammenwachsen sollten und wie sich die Zukunft des IT-Betriebs im Hinblick auf Teamstrukturen, Skills, Rollen und Prozesse verändern müssen.
Zum Whitepaper
Ist Ihnen die schillernde Sichtweise auf das Cloud-Thema unzureichend?
Wenn diese schillernde Sichtweise auf das „Cloud“-Thema für sich unzureichend ist, dann lesen Sie bitte weiter. Ziel dieses Artikels ist es, diese Perspektive auf das „Cloud“-Thema zu demystifizieren und aus dem Blickwinkel eines Ingenieurs und Informatikers den Versuch zu unternehmen, das Themenfeld „Cloud“ allgemeinverständlich zu erklären. Die Motivation hierfür ist, Experten anderer Fachgebiete ein Bild von der Cloud-Technologie zu vermitteln, denn „Cloud“ ist ein Werkzeug, mit dem in interdisziplinären Projekten sehr effiziente Lösungen für andere Fachgebiete realisierbar sind.
Lassen Sie uns gemeinsam die Fragen erörtern, was Cloud-Technologie ist, was zur Entwicklung der Cloud-Technologie geführt hat und werfen wir abschließend zusammen noch einen Ausblick auf die KI – künftige Informatik.
Was ist „Cloud-Technologie“ bzw. „Cloud Computing“?
Eingangs ist die Feststellung zu treffen, dass sich bisher keine einheitliche und allgemeingültige Definition für das Themenfeld „Cloud Computing“ bzw. „Cloud-Technologie“ herausgebildet und in der Fachwelt durchgesetzt hat. Hierzu ist generell anzumerken, dass dies in der schnelllebigen IKT-Branche eine durchaus übliche Situation ist. Entwickler und Start-ups mit neuen Ideen legen erst einmal los; wie dies dann später in die Geschichte der Informatik passt, wenn die Idee sich durchsetzt, wird den Historikern überlassen.
Eine in Fachkreisen oft herangezogene (und in der Praxis verwendete) Cloud-Definition, die „Cloud Computing“ bzw. „Cloud-Technologie“ aus fachlicher Sicht beschreibt, ist die der US-amerikanischen Standardisierungsstelle NIST (National Institute of Standards and Technology). Diese wird auch von der ENISA (European Network and Information Security Agency) genutzt.
Cloud-Computing-Definition 1
Cloud Computing ist ein Modell zur Ermöglichung eines allgegenwärtigen, bequemen, bedarfsgerechten Netzwerk-Zugriffs auf einen gemeinsamen Pool konfigurierbarer Computing-Ressourcen (z. B. Netzwerke, Server, Speicher, Anwendungen und Dienste), die mit minimalem Verwaltungsaufwand oder Interaktion mit dem Dienstanbieter schnell bereitgestellt und freigegeben werden können. Dieses Cloud-Modell setzt sich aus fünf wesentlichen Merkmalen, drei Dienstmodellen und vier Bereitstellungsmodellen zusammen.
Die Merkmale, Dienstmodelle, Bereitstellungmodelle werden in den nachfolgenden Abschnitten noch detailliert erläutert und an dieser Stelle nur der Vollständigkeit halber genannt.
Wesentliche Merkmale des Cloud-Computings (Servicemodelle)
- On-demand self-service (Dienstbereitstellung bei Bedarf): Die Bereitstellung der Computing Ressourcen (bspw. Rechenleistung, Speicher, etc.) kann von Nutzer selbst initiiert werden und läuft automatisch ohne Interaktion mit den Cloud Dienstleister ab.
- Broad network access (Breitbandige Netzanbindung): Die Dienstleistungen (Services) sind über das Netzwerk und über Standardschnittstellen verfügbar, wodurch deren Nutzung über eine große Breite von Plattformen (bspw. Smartphones, Tablets, Notebooks, IoT-Geräte etc.) möglich ist.
- Resource pooling (Bündelung von Ressourcen): Die Ressourcen des Cloud-Anbieters werden als Pool bereitgestellt, aus dem die Nutzer sich bedienen können (Multi-Tenant-Modell). Die Nutzer wissen dabei nicht, an welchen Ort sich die Ressourcen genau befinden. Es besteht jedoch die Möglichkeit, dass Sie den Speicherort (bspw. Land, Region, Rechenzentrum) vertraglich festlegen können.
- Rapid elasticity (schnelle Elastizität): Die Dienstleistungen (Services) können schnell und elastisch zur Verfügung gestellt werden, vielfach ist dies auch automatisiert möglich. Die Ressourcen scheinen daher aus Nutzerperspektive unendlich zu sein.
- Measured service (Messbare Dienstleistung): Cloud-Systeme steuern und optimieren die Ressourcennutzung automatisch. Dies kann überwacht, kontrolliert und berichtet werden. Damit wird sowohl für den Cloud Dienstleister als auch für den Nutzer, Transparenz bzgl. der genutzten Dienstleistungen (Services) geschaffen.
Die drei Dienstmodelle der Cloud-Lösungen
- Software-as-a-Service (SaaS)
- Platform-as-a-Service (PaaS)
- Infrastructure-as-a-Service (IaaS)
Die vier Bereitstellungsmodelle der Cloud-Computing-Dienste
- Private Cloud
- Community Cloud
- Public Cloud
- Hybrid Cloud
Cloud-Computing-Definition 2
Eine aus wirtschaftlicher Perspektive blickende Cloud-Definition findet man bspw. im Gabler-Wirtschaftslexikon:
Cloud Computing beinhaltet Technologien und Geschäftsmodelle, um IT-Ressourcen dynamisch zur Verfügung zu stellen und ihre Nutzung nach flexiblen Bezahlmodellen abzurechnen. Anstelle IT-Ressourcen, beispielsweise Server oder Anwendungen, in unternehmenseigenen Rechenzentren zu betreiben, sind diese bedarfsorientiert und flexibel in Form eines dienstleistungsbasierten Geschäftsmodells über das Internet oder ein Intranet verfügbar. Diese Art der Bereitstellung führt zu einer Industrialisierung von IT-Ressourcen, ähnlich wie es bei der Bereitstellung von Elektrizität der Fall war. Firmen können durch den Einsatz von Cloud Computing langfristige Investitionsausgaben (CAPEX) für den Nutzen von Informationstechnologie (IT) vermindern, da für IT-Ressourcen, die von einer Cloud bereitgestellt werden, oft hauptsächlich operationale Kosten (OPEX) anfallen.
In Publikationen zum Themenfeld „Cloud Computing“ bzw. „Cloud-Technologie“ werden vielfach Parallelen zu Industriellen Revolution gezogen. Dieser Epoche entstammt das Konzept der Massenproduktion, womit bestimme Waren und Dienstleistungen erst ermöglicht wurden. Teilweise wird „Cloud Computing“ sogar mit Wasser, Strom, Telefonie und anderen klassischen Versorgungsgütern gleichgesetzt und zugegeben, so ganz unberechtigt ist dieser Vergleich heute nicht mehr. Ausfälle von Cloud-Computing-Systeme entwickeln langsam das Potential ähnliche Einschränkungen des gesellschaftlichen Lebens zu bewirken, wie Serviceunterbrechungen bei klassischen Versorgungsgütern – auch kommt zur Produktion von klassischen Versorgungsgütern immer mehr und mehr Cloud-Technologie zum Einsatz.
Die wahrscheinliche Konsequenz hieraus wird sein, dass sich generell der Betrieb von Cloud-Systemen professionalisieren wird, d.h. es wird sich hierfür eine Klasse von spezialisierten Dienstleistern am Markt etablieren, deren Know-how und Leistungsfähigkeit nicht mal eben schnell von einer Unternehmens-IT-Abteilung eingeholt werden kann. Die hier oft referenzierte Aussage „The Cloud is just someone else's computer“, stimmt so nicht mehr; es ist deutlich mehr, wie wir in den nächsten Abschnitten sehen werden.
Sicher kann man noch weitere Quellen zu dem Themenfeld hinzuziehen, eine noch viel engere Eingrenzung wird man damit voraussichtlich nicht erreichen. Um Cloud-Technologie noch besser zu verstehen, werfen wir im nächsten Abschnitt einen Blick auf den Aspekt, welche geänderten Rahmenbedingungen und die sich hieraus ergebenden Herausforderungen in der Informatik die Grundlage zur Entwicklung der Cloud-Technologie gelegt haben.
Was führte zur Entwicklung der Cloud-Technologie?
Vor Entwicklung (und Einführung) der Cloud-Technologie basierten Ende des 20. Jahrhunderts IT-Anwendungen in Unternehmen auf der Client-Server-Architektur (vgl. Abbildung 1), die auch bis zum heutigen Tag Anwendung findet.
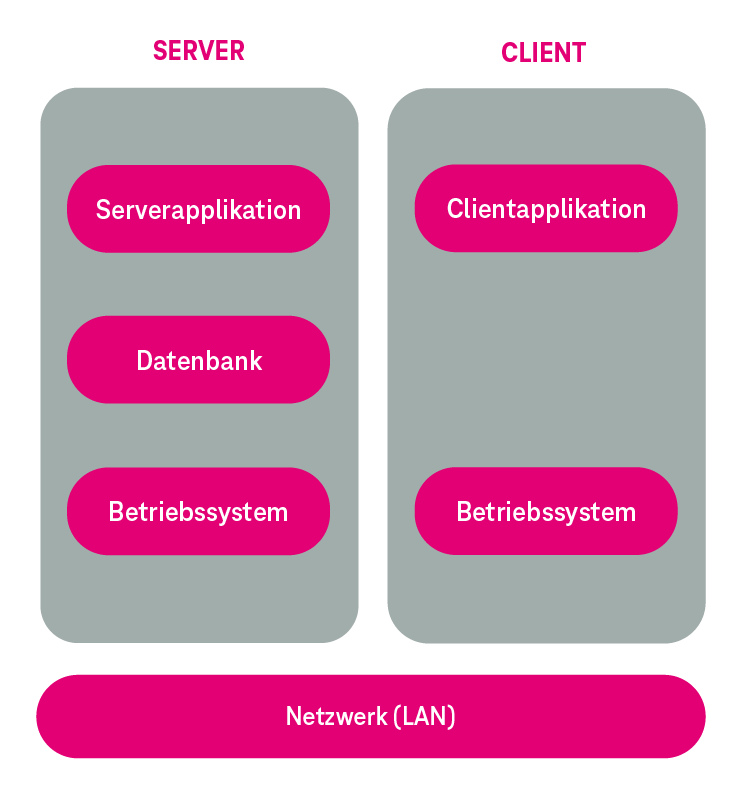
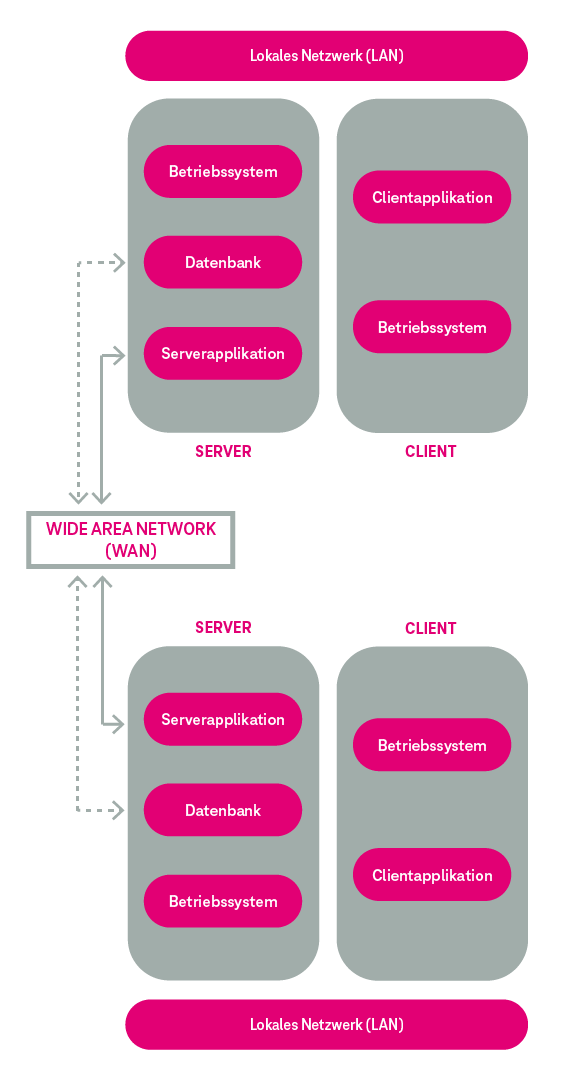
Die Nutzung einer Anwendung erfolgte üblicherweise über eine Client-Software, wobei Inkompatibilitäten diverser Clients oftmals der Grund für Betriebsstörungen auf den Arbeitsplatzrechnern waren. Für jede einzelne Anwendung erfolgte der Austausch von Daten zwischen verschiedenen Standorten eines Unternehmens mittels Server- oder Datenbankreplikation über angemietete Standleitungen (Leased Lines) (vgl. Abbildung 3). Der Aufwand für Betrieb und Wartung einer Anwendung war hierdurch entsprechend hoch.
Mit dem Aufkommen der Web-Browser-Technologie konnte eine erste Verbesserung der Situation derart realisiert werden, dass Anwendungen fortan als dynamische Web-Seiten im internen Netz bereitgestellt werden. Der Web-Browser als universeller „Client“ substituierte die proprietäre Client-Software auf den Arbeitsplatzrechner (vgl. Abbildung 2), jedoch ließen sich Inkompatibilitäten aufgrund des zu dieser Zeit herrschenden „Browserkriegs“ nicht ganz ausschließen. Die damals neue Web-Browser-Technologie legte den Grundstein für eine der ersten großen öffentlichen Klasse von Internet-Anwendungen, die Online-Shops.
Typischerweise haben Online-Shops über das Jahr eine sehr volatile Auslastungsverteilung; bspw. ist diese im Weihnachtsgeschäft sehr hoch, am Jahresanfang dann sehr gering. Jedoch müssen die Online-Shop-Betreiber in IKT-Technik investieren, die die höchsten Auslastungsspitze bearbeiten kann. Hierdurch entstehen über das Jahr betrachtet Unterauslastungen der IKT-Technik.
Für die Rechenzentrumsbetreiber galt, diese technisch verkaufbar zu machen (bspw. in dem man Kunden über das Internet nutzbare virtuelle Server oder Online-Speicher offeriert). Die technische Realisierung dieser neuen Portfolioelemente bedingte einen Paradigmenwechsel in der Softwareentwicklung, welche die Grundlage für die Cloud-Technologie gelegt hat.
Die feste Koppelung einer Anwendung an eine bestimmte Hardware wurde aufgehoben. Auch stellte die Skalierungsgrenze einer Hardware fortan nicht mehr die Skalierungsgrenze einer Anwendung da. Die nun fragmentarisch verkaufbare Rechenleistung wurde Kunden mit dem Slogan „You only pay, what you use“ angeboten. Der Cloud-Markt wurde geschaffen!
Rückblickend ist jedoch festzustellen, gut, dass es so war. Denn die hohe Flexibilität der Cloud-Technologie, die beispielweise die kostengünstige Bereitstellung hoher Rechenleistungen für einen begrenzten Zeitraum ermöglicht, ist heute eine der wesentlichen Grundlagen für von uns täglich genutzte Internetservices.
Aufbau und Funktionsweise der Cloud-Technologie
Im Zuge der Entwicklung der Cloud-Technologie ist für dieses Informatik-Fachgebiet ebenfalls der hierzu erforderliche Technolekt entstanden. Dieser wird nun genutzt, um anhand der Erklärung einzelner Elemente der Terminologie den Aufbau und die Funktionsweise der Cloud-Technologie zu erläutern.
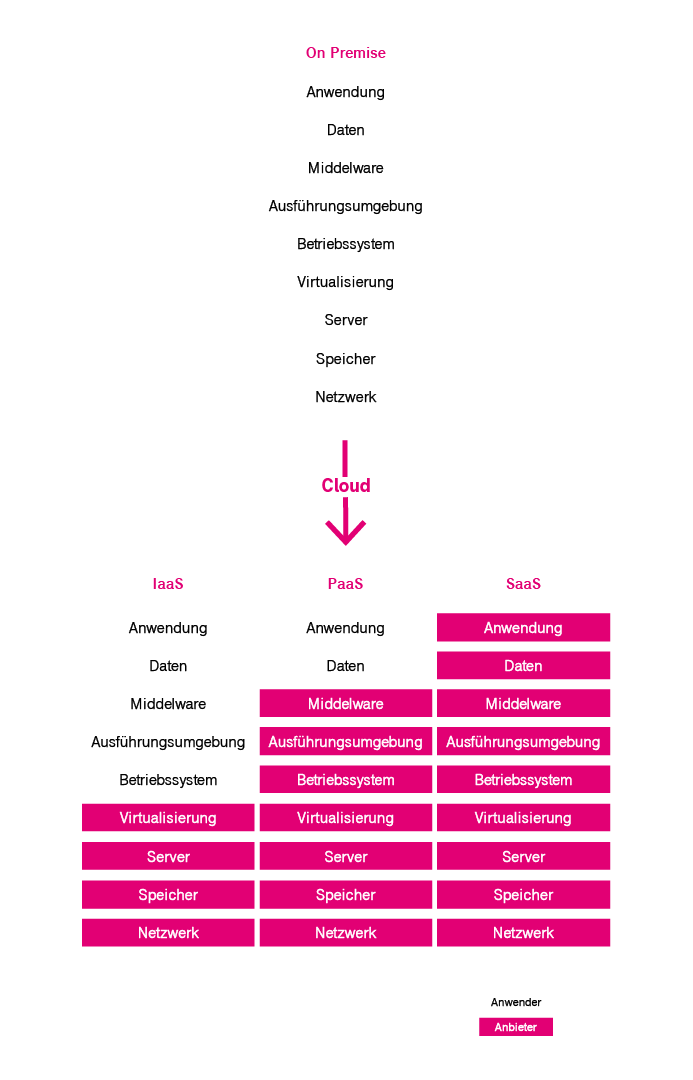
On Premise versus Cloud
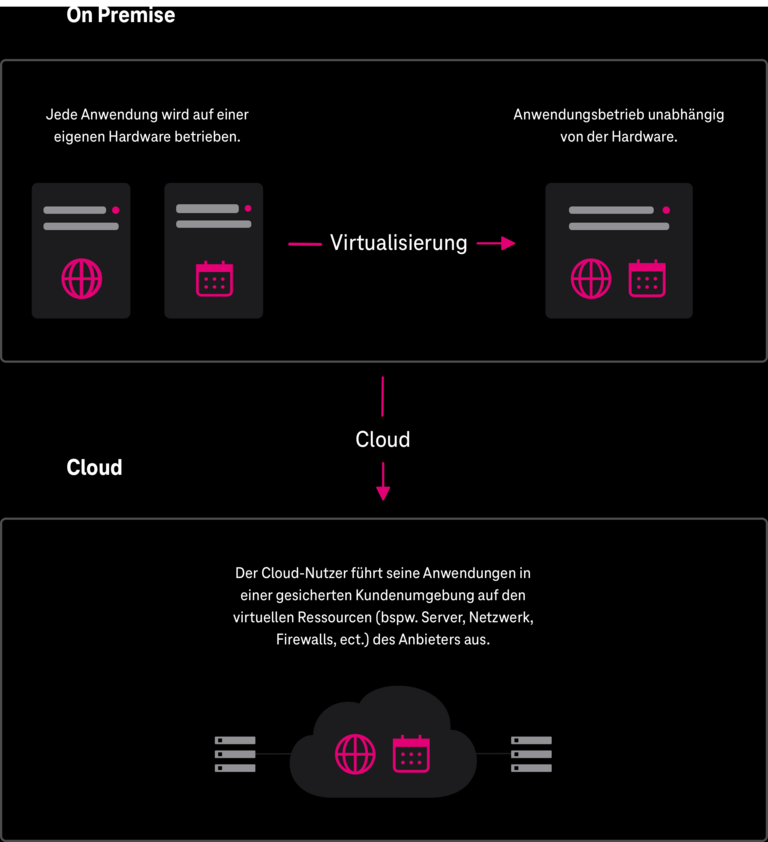
Unter dem Begriff „on Premise“ versteht man allgemein, dass eine Anwendung vor Ort beim Anwender in dessen IT-Räumlichkeiten betrieben wird. Dies kann a) klassisch erfolgen, d.h. die Anwendung wird direkt auf der dedizierten Hardware betrieben, oder b) virtualisiert, d.h. die Anwendungen werden in einer virtuellen Umgebung betrieben, und damit unabhängig von einer dedizierten Hardware.
Unter dem Begriff „Cloud“ versteht man allgemein, dass die Anwendung in einer gesicherten virtuellen Kundenumgebung im Rechenzentrum des Cloud-Dienstleisters betrieben wird. Ist eine Migration von „on Premise“- Anwendungen in die Cloud beabsichtigt, entscheiden die beiden Fälle über die grundsätzlich anzuwendende Migrationsstrategie. Abbildung 4 verdeutlicht den Sachverhalt.
Cloud-Computing-Dienstmodelle: Infrastructure-as-a-Service, Platform-as-a-Service, Software-as-a-Service
Die Cloud-Dienstmodelle werden gemäß der NIST-Cloud-Definition (siehe oben) nach einem Schichtenmodell unterteilt (vgl. Abbildung 5). Ein Schichtenmodell ist in der IKT-Branche ein typischerweise vorzufindendes Strukturierungsprinzip für die Architektur von Softwaresystemen. Einzelne Aspekte des Softwaresystems werden einer Schicht zugeordnet. Hierbei sind die Abhängigkeitsbeziehungen zwischen den Aspekten so festgelegt, dass Aspekte einer höheren Schicht nur Aspekte der unterliegenden Schichten verwenden dürfen. Auch sind die Schnittstellen zwischen den Schichten fest definiert. Nicht definiert ist die Software-Implementierung, mit der ein Aspekt in einer Schicht realisiert wird. Dies ermöglicht in komplexen Software-Systemen nur den, den Aspekt betreffenden Teil einer Software-Implementierung, gegen eine verbesserte Variante auszutauschen.
Schichtenmodelle bilden in der IKT-Branche auch die essenzielle Grundlage für die arbeitsteilige Zusammenarbeit, indem einzelne Teams für einzelne Aspekte des Softwaresystems verantwortlich sind. Und in Kombination mit einer Arbeitsorganisation nach DevOps-Methodik können so Softwaresysteme kontinuierlich und unterbrechungsfrei weiterentwickelt und betrieben werden; klassische Software-Versionswechsel gibt es hier nicht mehr, sobald eine neue verbesserte Funktionalität fertig entwickelt und erfolgreich getestet ist, wird sie sofort im Produktionssystem aktiv.
Doch kommen wir nun zurück zu den Cloud-Dienstmodellen, diese sind (vgl. Abbildung 5):
- On Premise: On Premise ist hier nur der Vollständigkeit halber in der Abbildung 5 gezeigt, um einen besseren Vergleich zur den Cloud-Dienstmodellen zu ziehen. On Premise ist nicht Bestandteil eines Cloud-Dienstmodells (vgl. oben)
- Infrastructure-as-a-Service (IaaS): Auf dieser Ebene bietet der Cloud-Dienstleister dem Anwender die komplette Hardware (IT-Ressourcen) wie bspw. Rechenleistung, Speicher, Netzwerkanbindung, Öffentliche IP-Adresse, usw. an. Dabei werden die Instanzen, die der Anwender in Anspruch nimmt, typischerweise virtuell bereitgestellt (die Bereitstellung dedizierter Maschinen ist bei einigen Cloud-Dienstleistern möglich). Der Anwender muss sich die benötigten IT-Ressourcen aus dem Angebot des Cloud-Dienstleisters selbst zusammenstellen. Er hat dabei die Kontrolle über das Betriebssystem und die Anwendungen, ferner die Verantwortung für die Überwachung und den sicheren Betrieb der Maschine(n).
- Platform-as-a-Service (Paas): Auf dieser Ebene bietet der Cloud-Dienstleister dem Anwender zusätzlich zur Hardware eine komplette Arbeitsumgebung an, die sich primär an Softwareentwickler richtet, um Cloud-basierte Anwendungen zu erstellen und zu betreiben. Der Anwender kontrolliert hier nicht mehr die zugrundeliegenden Cloud-Infrastruktur (bspw. Server, Betriebssystem, Speichern, Netzwerkanbindung, etc.). Er hat die Kontrolle über die bereitgestellte Arbeitsumgebung und ggf. über die Konfigurationseinstellungen für die Anwendungs-Hosting-Umgebung.
- Software-as-a-Service (Saas): Auf dieser Ebene bietet der Cloud-Dienstleister dem Anwender vollständige Software-Anwendungen an, die von verschiedenen Endgeräten aus zugänglich sind. So wird auch mobiles Cloud-Computing ermöglicht. Der Anwender kontrolliert hier nur noch benutzerspezifische Anwendungseinstellungen. Entwicklung und Betrieb der Anwendung einschließlich der Bereitstellung und Überwachung der unterliegen Hardware liegen im Verantwortungsbereich des Cloud-Dienstleisters.
Cloud-Computing-Dienste – Unterschiede einfach erklärt
Eine Möglichkeit, die Unterschiede bei der Erstellung und dem Betrieb von IKT-Anwendungen durch Nutzung der Cloud-Dienstleistungen IaaS, PaaS, und SaaS im Vergleich zu On Premise zu erläutern, lässt sich gut an dem Beispiel der „Produktionskette“ für ein Pizza-Abendessen erläutern. Wenn Sie alle Zutaten vorab einkaufen, den Pizzateig selbst anfertigen und selbst belegen, die rohe Pizza dann bei sich zu Hause im Ofen backen und sich selbst den Tisch für das Pizza-Abendessen decken, dann ist das On Premise.
Reduzieren Sie die Fertigungstiefe Ihres Pizza-Abendessen dadurch, dass Sie eine Tiefkühl-Fertigpizza kaufen, die Sie nur noch im Ofen backen und danach auf Ihren selbst gedeckten Tisch platzieren, dann wäre ein Beispiel für IaaS. Reduzieren Sie die Fertigungstiefe Ihres Pizza-Abendessen nochmals weiter dadurch, dass Sie ein Pizza-Lieferdienst mit der Erstellung, dem Backen und der Lieferung der heißen Pizza beauftragen (d.h. Sie müssen nur noch den Tisch für die Pizza-Abendessen decken), dann ist ein Beispiel für PaaS. Wollen Sie einfach nur eine gute Pizza zum Abendessen haben ohne sich um irgendwelche Details der „Produktionskette“ kümmern zu müssen, dann setzen sie sich an den gedeckten Tisch beim nächsten Italiener, das ist dann SaaS.
Bereitstellungsmodelle: Wie unterscheiden sich Public & Business-Cloud-Modelle?
Die Cloud-Bereitstellungsmodelle, d.h. für welche Kategorien von Anwendern die Bereitstellung der Cloud erfolgt, werden gemäß der NIST-Cloud-Definition (siehe oben) wie folgt unterteilt:
- Private Cloud: Die Cloud-Infrastruktur wird zur ausschließlichen Nutzung für die Anwender einer einzigen Organisation bereitgestellt. Sie kann von der Organisation oder in deren Auftrag von einer dritten Partei (Cloud-Servicedienstleister) verwaltet und betrieben werden.
- Community Cloud: Die Cloud-Infrastruktur wird zur ausschließlichen Nutzung durch eine Gemeinschaft von Anwendern aus verschiedenen Organisationen bereitgestellt, die ein gemeinsames Anliegen (bspw. Projekt) haben. Sie kann Eigentum einer oder mehrerer Organisationen dieser Gemeinschaft oder einer dritten Partei sein (oder einer Kombination davon) und von diesen verwaltet und (auch im Auftrag durch einen Cloud-Servicedienstleister) betrieben werden.
- Public Cloud: Die Cloud-Infrastruktur ist für die offene Nutzung durch die Allgemeinheit vorgesehen. Sie kann Eigentum einer geschäftlichen, akademischen oder staatlichen Organisation (oder einer Kombination davon) sein und von diesen verwaltet und (auch im Auftrag durch einen Cloud-Servicedienstleister) betrieben werden.
- Hybrid Cloud: Die Cloud-Infrastruktur ist eine Zusammensetzung aus zwei oder mehreren verschiedenen Cloud-Infrastrukturen (privat, gemeinschaftlich, öffentlich), die zwar getrennte Infrastrukturen bleiben, jedoch über standardisierte oder proprietäre Technologien so miteinander verbunden sind, dass sie sich wie eine Cloud-Infrastruktur verhalten.
Über die vier von NIST definierten Cloud-Bereitstellungsmodelle sind in der Literatur und den einschlägigen Publikationen noch zahlreiche weitere Bereitstellungsmodelle zu finden. Im Kern der Sache beschreiben die Cloud-Bereitstellungsmodelle „Cluster von Rechteeinstellungen“. Die Rechte- und Zugriffssteuerungssysteme moderner Cloud-Plattformen lassen mittlerweile sehr feingranulare Konfigurationen zu, so dass die genannten Modelle in der NIST-Definition zwischenzeitlich als grobe Orientierungshilfe und nicht als Beschränkung zu verstehen sind.
Cloud Computing für Unternehmen: Welche Regionen und (Verfügbarkeits-)Zonen brauche ich?
Die geografische Struktur einer Cloud teilt sich in Regionen und (Verfügbarkeits-)Zonen auf (vgl. Abbildung 6). Der Anwender muss bei der Zusammenstellung der von ihm benötigten IT-Ressourcen aus dem Angebot des Cloud-Dienstleisters festlegen, an welcher geografischen Lokation (Rechenzentrum) er diese haben möchte. Diese Entscheidung hat bspw. aufgrund der Signallaufzeiten auf den weltweiten Datenleitungen eine signifikante Auswirkung auf die spätere Geschwindigkeit der Anwendung.
So ist es für eine Anwendung, die für Kunden in Nordamerika bestimmt ist, nicht sinnvoll, diese aus einem Rechenzentrum im Asien heraus zu betreiben, wenn Geschwindigkeit für die Kunden ein wichtiges Kriterium ist. Folgendes gilt es hier zu berücksichtigen:
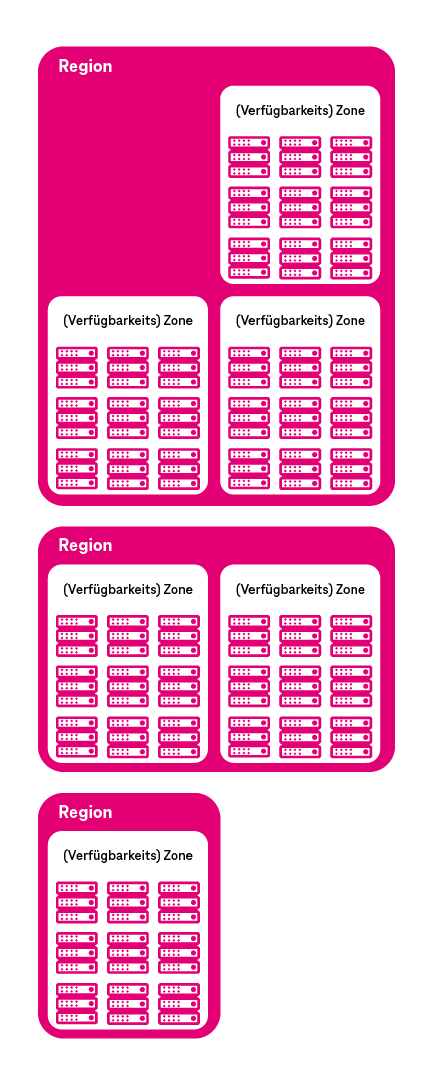
Neben diese primären geografischen und technischen Eigenschaften unterschieden sich die Regionen und Zonen sekundär noch in den Preisen, die für vergleichbare Services zu entrichten sind und im Angebotsumfang der Services (nicht jeder Service ist in jeder Region und Zone verfügbar). Die Entscheidung, in welcher Region(en) und in welcher (Verfügbarkeits-)Zone(n) man seine Anwendung betreibt, ist eine signifikante Architekturentscheidung, die vorab wohl zu überlegen ist.
Betreibt man bspw. eine Online-Shop-Plattform, dann ist sinnvoll, die Anwendung in die Region zu legen, in der sich auch die Kunden befinden, damit aufgrund der geringen Latenzzeit die Anwendung performant bei den Kunden läuft. Ferner ist es in dem Szenario ratsam, die Anwendung zur Steigerung der Verfügbarkeit redundant auf mehrere (Verfügbarkeits-)Zonen aufzuteilen. Benötigt man bspw. für die Produktentwicklung eine hohe Rechenleistung für mehrtägige Simulationsrechnungen (bspw. für virtuelle Kraftfahrzeug-Crashtests oder auch Strömungssimulationen an virtuellen Luftfahrzeugen) und es kommt auf ein paar Minuten mehr oder weniger bei der Datenübertragung nicht an, dann ist es sinnvoll, eine Region und (Verfügbarkeits-)Zone weltweit zu wählen, in der Rechenleistung und Arbeitsspeicher preisgünstig angeboten werden.
Cloud-Server
Cloud-Server werden als virtuelle (simulierte) Server auf einer physikalischen Hardware (realer Server) bereitgestellt. Hierzu wird eine „Hypervisor“ genannte Software eingesetzt, die es ermöglicht, mehrere virtuelle Server auf einer physikalischen Hardware zu betreiben („Hypervisoren“ werden in einem nachfolgenden Abschnitt nochmal detailliert erläutert). Da Cloud-Server virtuelle Server sind, lässt sich die Ausstattung mit Prozessorleistung, Arbeitsspeichergröße, Festplattengröße innerhalb der möglichen Systemgrenzen frei dem Bedarf der Anwendung anpassen (vgl. Abbildung 7).
Das Serviceangebot von Cloud-Plattformen umfasst auch einen „Image-Server“, der fertig vorkonfigurierte Festplatten-Images mit verschiedenen vorinstallierten Betriebssystemen für die Erstellung eines Cloud-Servers bereithält, so dass die zeitaufwändige Betriebssysteminstallation bei der Erstellung eines neuen Cloud-Servers entfällt.
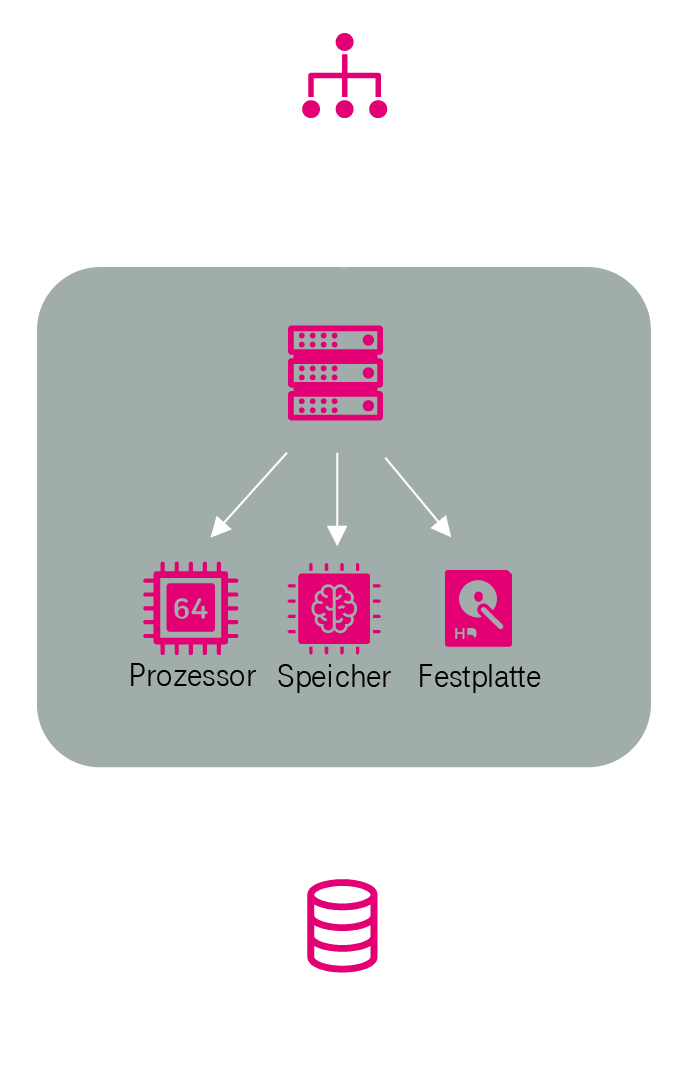
Image-Server: Der Image-Server stellt Festplatten-Images mit vorkonfigurierten Betriebssystemen und Anwendungen bereit. Des Weiteren ist die Vorhaltung und Bereitstellung von kundenspezifischen Festplatten-Images möglich.
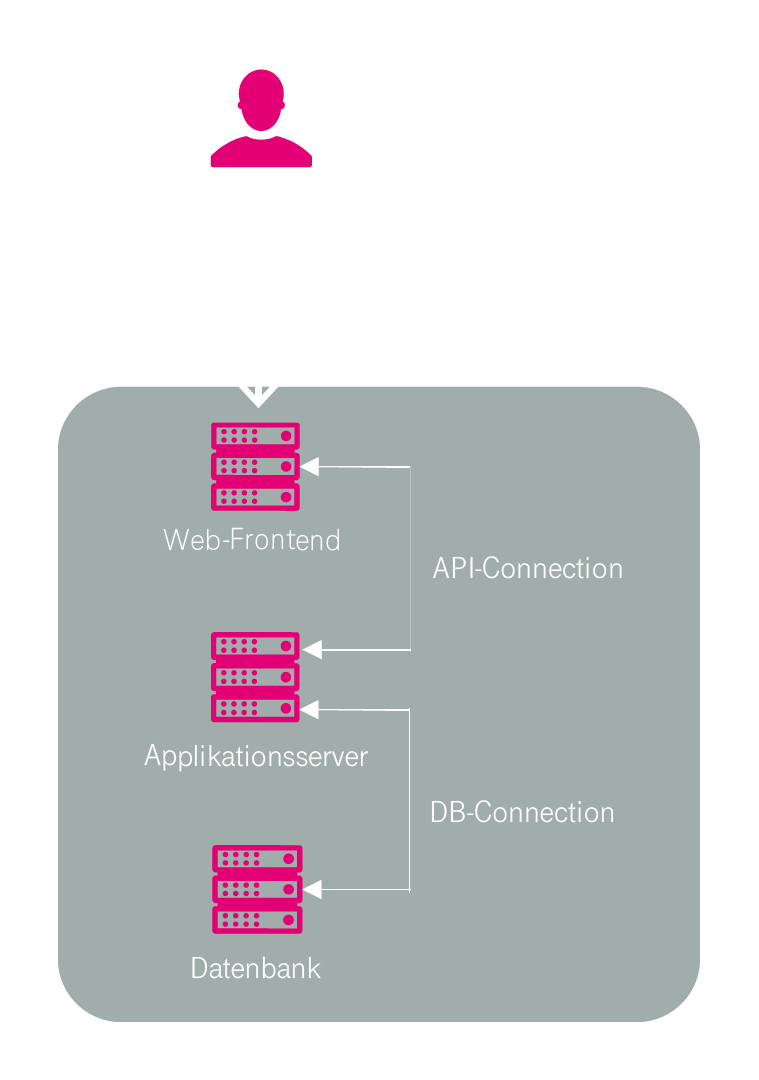
3-Tier-Architektur
Einleitend ist anzumerken, dass die 3-Tier-Architektur (deutsch: Drei-Schichten-Architektur, vgl. Abbildung 8) von Software-Systemen ein von der Cloud-Technologie unabhängiges Paradigma ist. In Kombination mit Cloud-Technologie ermöglicht die 3-Tier-Architektur eine sehr effiziente Art einer Skalierung, d.h. die bedarfsabhängige Anpassung der Cloud an die benötigte Leistung der Anwendung (vgl. nächsten Abschnitt). Sie wird deshalb an dieser Stelle kurz angesprochen.
Bei der 3-Tier-Architektur wird die Anwendung generisch in drei Ebenen eingeteilt, diese sind:
- Client-Tier (deutsch: Präsentationsschicht)
- Application-Server-Tier (deutsch: Logikschicht)
- Data-Server-Tier (deutsch: Datenhaltungsschicht)
Die 3-Tier-Architektur wird typischerweise zur serverseitigen Realisierung von Web-Anwendungen verwendet. In diesem Fall sind die drei Schichten wie folgt bezeichnet:
- Web-Frontend (steuert das Design und Layout der Web-Anwendung))
- Application-Server (steuert die Anwendungslogik)
- Data-Server (enthält die Datenbank der Anwendung)
Durch diese Dreiteilung der Anwendung kann mittels Cloud-Technologie sehr gut erkannt werden, welcher Teil der Anwendung welchen Leistungsbedarf hat, so dass die Cloud dies entsprechend bereitstellen kann.
Skalierung (vertikal und horizontal) – Cloud Optimization
Unter „Skalierung“ bzw. „skalierbar“ wird die Fähigkeit der Cloud verstanden, sich ansteigenden bzw. nachlassenden Leistungsanforderungen der Anwendungen dynamisch anzupassen. Prinzipiell unterscheidet man vertikale Skalierung und horizontale Skalierung.
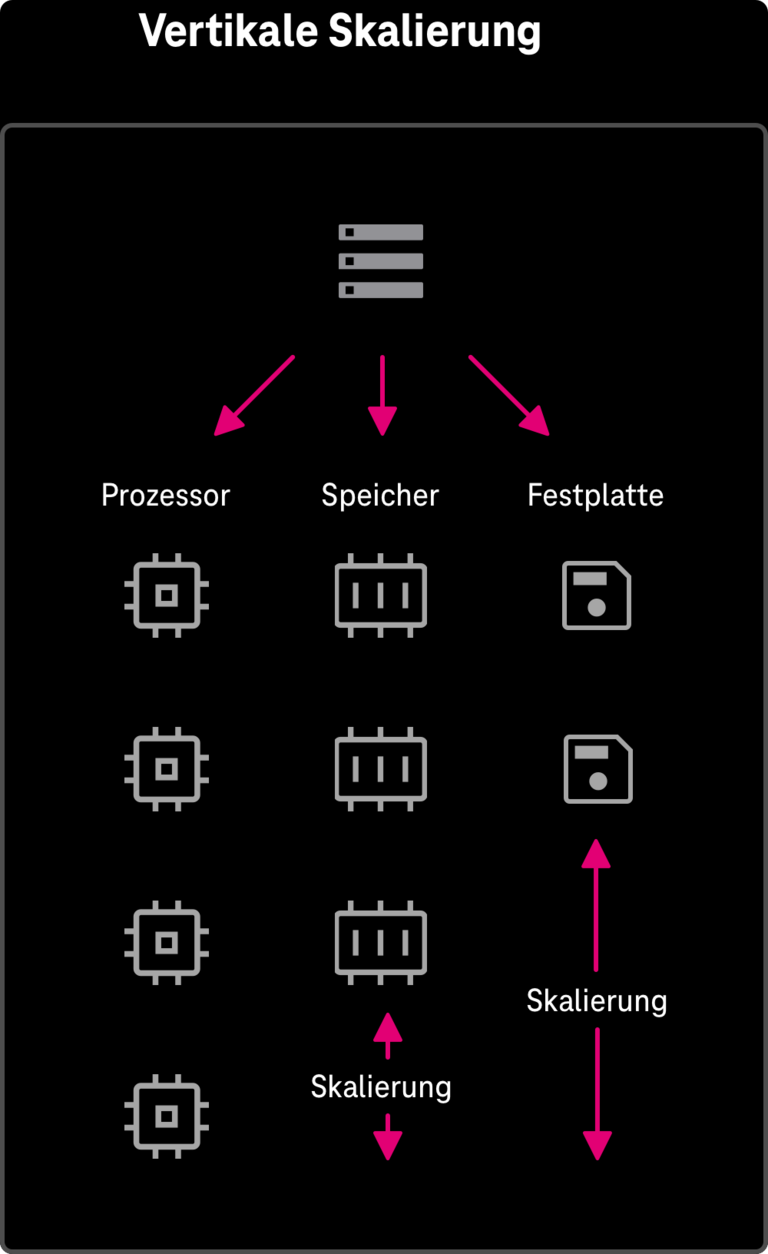
Bei der vertikalen Skalierung (vgl. Abbildung 9) erfolgt die bedarfsabhängige Anpassung der Leistungsfähigkeit eines virtuellen Cloud-Servers durch dynamisches Hinzufügen bzw. Rücknahme von virtuellen Ressourcen (bspw. Anzahl der CPU-Cores, Arbeitsspeicher, Festplattenkapazität) zur Laufzeit des Systems. Mit vertikaler Skalierung kann die Leistungsfähigkeit unabhängig von der Softwareimplementierung gesteuert werden, wodurch On Premise betriebene Anwendungen sehr schnell in die Cloud transferiert und dort dynamisch betrieben werden können (diese Migrationsverfahren wir als Lift-and-Shift bezeichnet).
Es gilt zu beachten, dass die hierdurch erreichbare maximale Leistungsfähigkeit eines virtuellen Cloud-Servers aufgrund der maximal möglichen Anzahl von Ressourcen, die diesem in der Cloud-Plattform zugeordnet werden können, nach oben begrenzt ist.
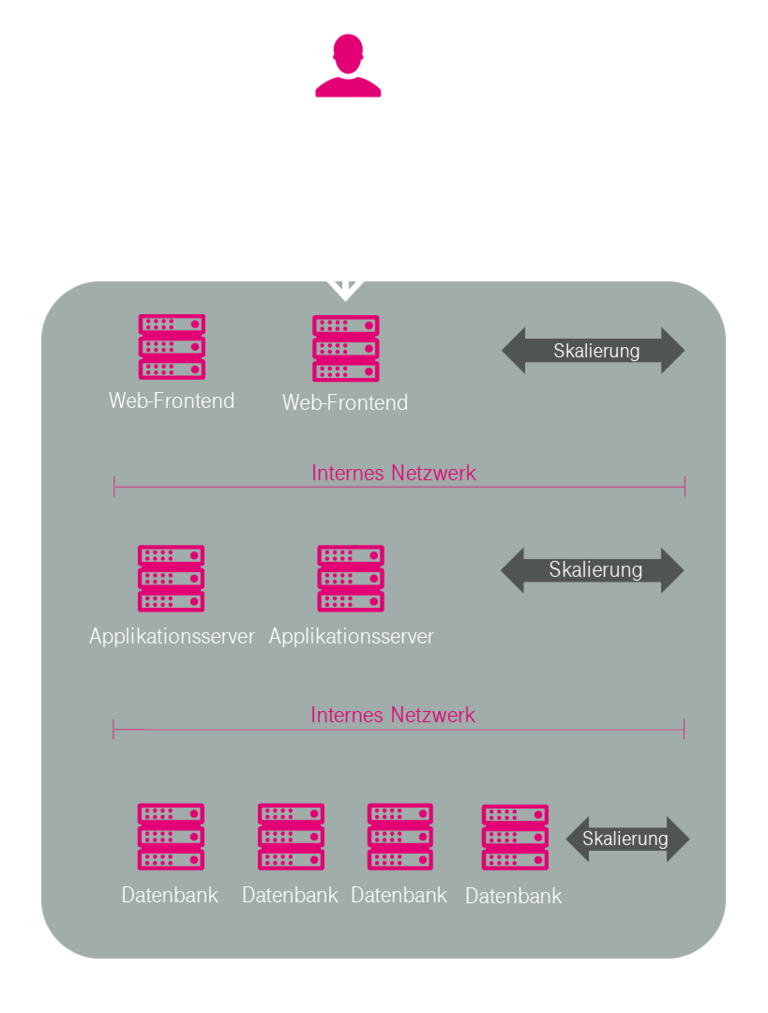
Bei der horizontalen Skalierung (vgl. Abbildung 10) erfolgt die bedarfsabhängige Anpassung der Leistungsfähigkeit der Cloud durch dynamisches Hinzufügen bzw. Entfernen von virtuellen Cloud-Servern, auf denen sich die Last parallel aufteilt. Die Architektur der Anwendung muss diese Art der Skalierung unterstützen (eine 3-Tier-Architektur ist hierfür vorteilhaft). Die maximal mögliche Leistungsfähigkeit eines Cloud-Systems ist dadurch (theoretisch) unbegrenzt skalierbar. Allerdings muss die Softwareimplementierung einerseits und die zu bearbeitende Aufgabe andererseits parallelisierbar sein.
Vertikale und horizontale Skalierung können miteinander kombiniert werden. Auf Basis des Reportings einer Cloud-Plattform wird die Auslastung einzelner Komponenten kontinuierlich erfasst. Basierend auf diesen Werten wird dann die Skalierungsautomatik für eine Cloud-Anwendung so eingestellt, dass immer nur die gerade benötigte Leistung bereitgestellt (und berechnet) wird. Leerlaufende, ungenutzte, jedoch bezahlte Computer-Ressourcen gehören damit der Vergangenheit an.
Server Virtualisierung / Hypervisoren
Die essenzielle technische Grundlage zur Realisierung von Cloud-Plattformen wird von einem System bereitgestellt, das in der praktischen Informatik als Hypervisor bzw. als Virtual Machine Monitor bezeichnet wird.
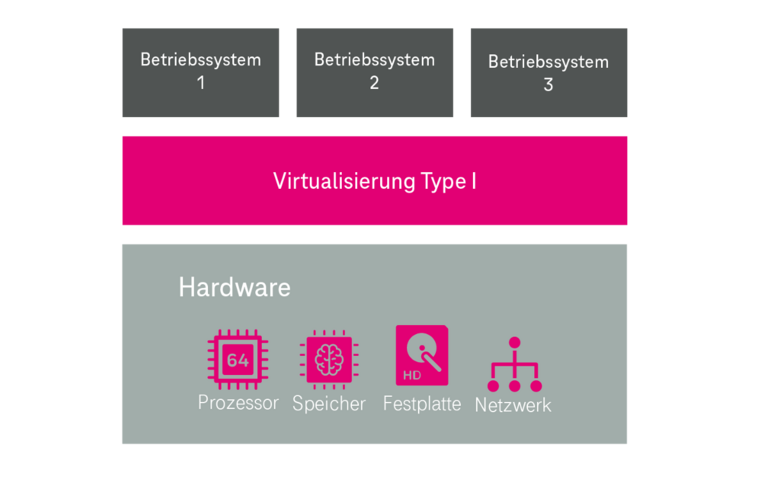
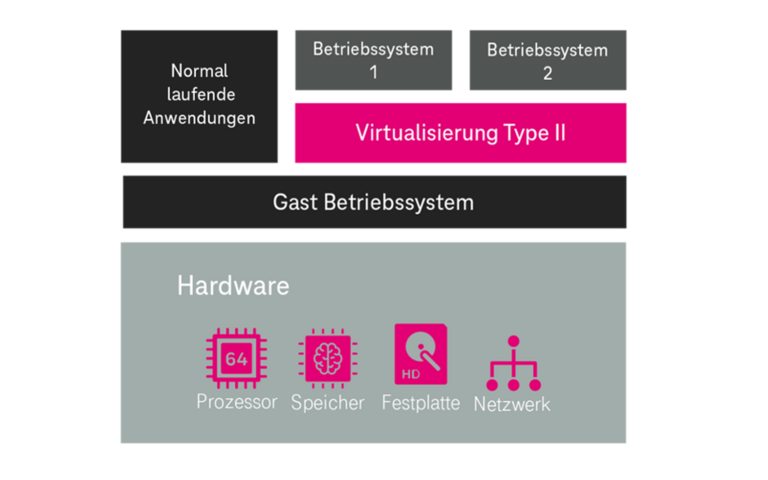
Ein Hypervisor ist „ein Stück Software“, welches eine abstrahierende Schicht zwischen einer real vorhandenen Hardware (und einem ggf. darauf vorhanden Gast-Betriebssystem) und weiteren Betriebssystemen schafft. Diese weiteren Betriebssysteme werden in der vom Hypervisor geschaffenen virtuellen (Hardware-)Umgebung (bspw. CPU-Cores, Arbeitsspeicher, Festplatte, etc.) installiert; man bezeichnet diese dann als virtuelle Betriebssysteme. Ein Hypervisor ermöglicht den unabhängigen und logisch abgegrenzten Betrieb mehrerer virtueller Betriebssysteme auf einer real vorhandenen Hardware. Er teilt die real vorhandene Rechenleistung der realen Hardware den virtuellen Betriebssystemen dynamisch zu. Virtuelle Cloud-Server und die vertikale Skalierung basieren auf der Hypervisor-Technologie.
Die Ursprünge der Hypervisor-Technologie gehen u.a. auf die Dissertation „Architectural Principles for Virtual Computer Systems“ von Robert P. Goldberg aus den Jahre 1973 zurück. Hierin werden die heute noch gebräuchlichen 2 Typen
✓ native Hypervisor (Type 1) und
✓ hosted Hypervisor (Type 2)
definiert (vgl. Abbildung 11). Die Hypervisor-Technologie ist hierdurch als eine sehr ausgereifte Technologie anzusehen.
In diesem Abschnitt wurden die meistgenutzten Terminologien der Cloud-Technologie erläutert. Auf diese werden Sie üblicherweise immer wieder im Zusammenhang mit dem Thema Cloud treffen und ich hoffe, Ihnen hiermit etwas mehr Orientierung in diesem Umfeld gegeben zu haben.
Wie arbeitet man mit einer Cloud?
Ein Nutzer kann typischerweise mit einer Cloud-Plattform über folgende zwei Zugangsmöglichkeiten arbeiten:
- über ein Web-Portal (Cloud-Console), für die direkte Interaktion mit der Cloud-Plattform
- über eine Programmier-Schnittstelle (API), mittels der man programmgesteuert (automatisiert) Aktionen in der Cloud-Plattform ausführen und Resultate und Zustände abfragen kann.
Die Cloud-Konsole (und auch die API) bildet hiermit ein "Cockpit" zum Aufbau und Betrieb eines "virtuellen Rechenzentrums" für ein Unternehmen. Die IT-Verantwortlichen können damit die Unternehmens-ITK virtuell aufbauen und betreiben. Dies verkürzt die Realisierungszeiten, steigert die Flexibilität und ermöglicht die ortsunabhängige Tätigkeit der Mitarbeiter. Service-Unterstützungsleistungen von dritter Seite können bei Bedarf schneller erbracht werden. Durch die API-Beschreibungssprachen kann die Struktur, der Aufbau und die Funktion des „virtualisierten Rechenzentrums“ nachvollziehbar, wiederholbar und prüfbar dokumentiert und überwacht werden.
Im ersten Eindruck wirken Web-Portale von Cloud-Plattformen sehr komplex. Durch ihren, an der oben beschriebenen IaaS/PaaS/SaaS-Systematik angelehnten sehr stringenten und strukturierten Aufbau, gelingt eine Einarbeitung jedoch in kurzer Zeit.
Beispiel für die Struktur einer Cloud-Plattform
IAAS Funktionalitäten
Netzwerk
- Öffentliche IP-Adressen
- NAT-Gateway
- Subnetze
- Domain Name Service (DNS)
- Virtual Private Network (VPN)
- Load Balancer
- Firewall
- etc.
Computing
- virtuelle Prozessoren (Cores)
- virtueller Arbeitsspeicher
- etc.
Speicher
- virtuelle Datenträger (bspw. Festplatte)
- Backup-Services
- etc.
Sicherheit
- Identitätsmanagement
- Zugriffsmanagement
- Schlüsselverwaltung
- etc.
Verwaltung
- Kostenmanagement
- Ressourcenmanagement
- Monitoring
- etc.
PAAS-Funktionalitäten
Betriebssysteme
- Image Services (bspw. vorkonfigurierte Linus- und Windows-Maschinen)
Datenbanken
Container-Services
etc.
SAAS-Funktionalitäten
Filesystem ("HiDrive")
E-Mail Service
Online Office Anwendung
Webhosting (mit Editionstools)
Online Shop
VoIP-Technologie
etc.
Des Weiteren zwei konkrete Beispiele anhand der Open Telekom Cloud (Abbildung 12) und der Microsoft Azure (Abbildung 13).
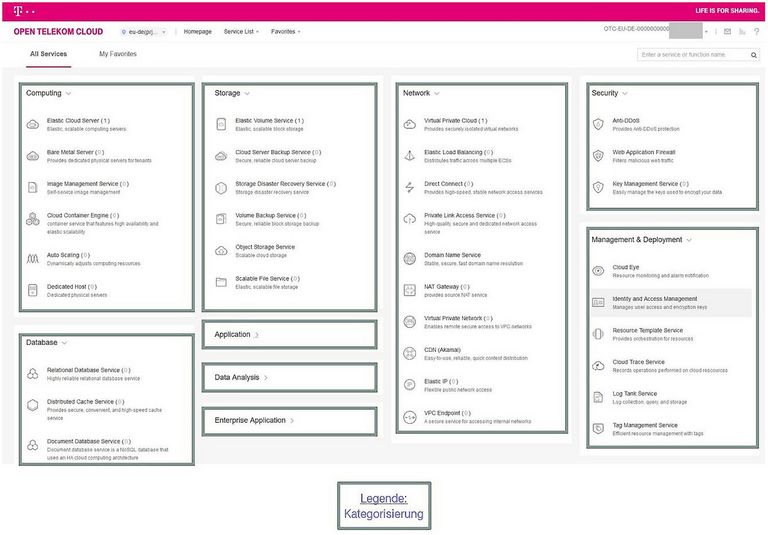
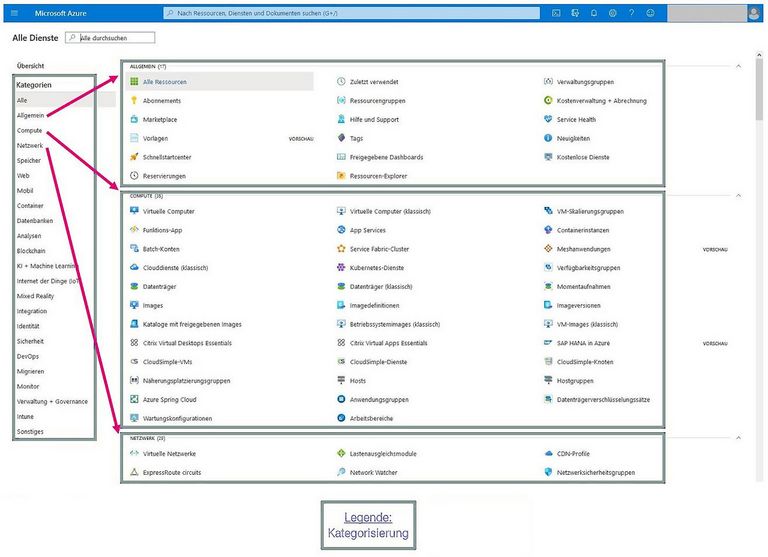
Kann man die Bedienung einer Cloud-Plattform an einem einfachen Beispiel verdeutlichen?
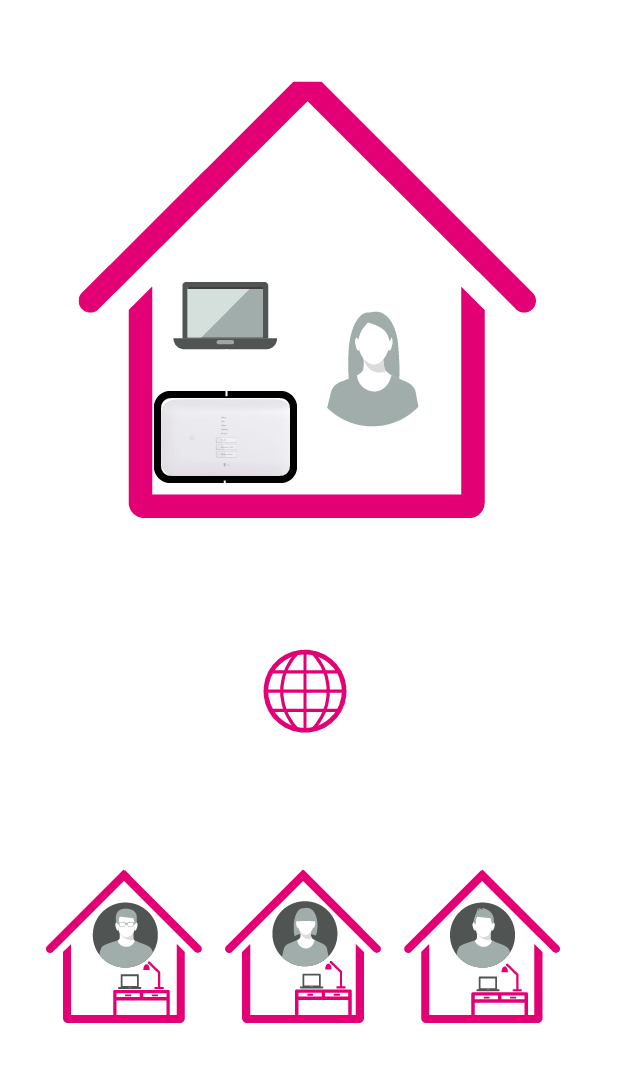
Ja, hierfür nutzen wir ein Szenario aus dem Leben des Autors als Erziehungsberechtigten eines Gymnasialschülers. In der Informatik-Projektwoche hat eine Gruppe die Aufgabe bekommen, bei einem Schüler zu Hause einen Web-Server aufzusetzen und im öffentlichen Internet so bereitzustellen, dass die anderen Schüler darauf zugreifen können. Für den Web-Server steht den Schülern als Infrastruktur der Zugangsrouter (bspw. ein Speedport) und ein Computer zu Verfügung. Abbildung 14 verdeutlicht dieses Szenario.
Die Struktur, die die Schüler zur Realisierung des Webservers in der Projektwoche physikalisch aufgebaut haben, lässt sich einfach und schnell mit einer Cloud-Plattform „zusammenklicken“, indem man die wesentlichen funktionalen Komponenten identifiziert und virtuell in der Cloud-Plattform nachbildet. Abbildung 15 verdeutlicht dies.
Objekte, die in der Cloud Konsole anzulegen sind, sind in der untenstehenden Abbildung dunkelgrau hervorgehoben. Diese sind:
- öffentliche IP Adresse
- NAT-Gateway
- Port-Weiterleitung
- interne Gateway IP-Adresse
- internes Subnetz
- interne Server IP-Adresse
- Betriebssystem
- virtuelle Maschine
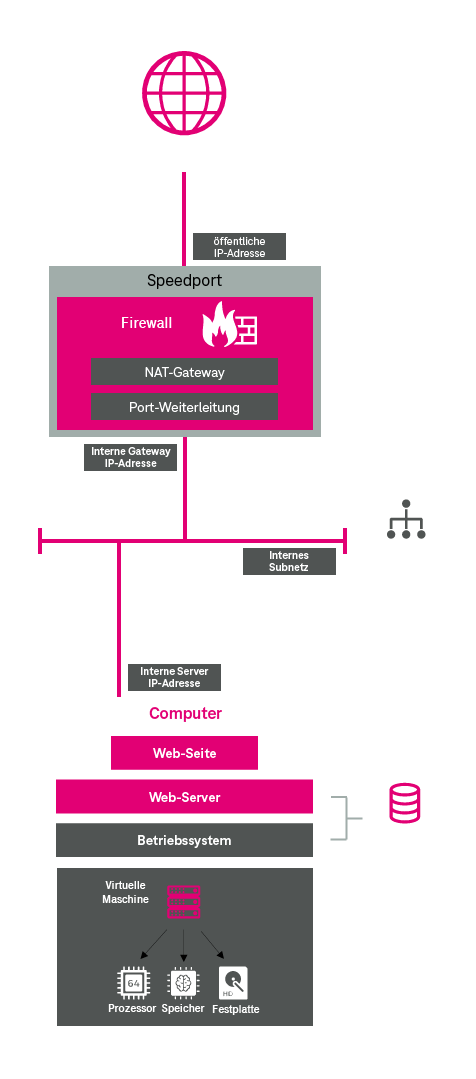
Die Vorgehensweise sei an dieser Stelle kurz skizziert, sie ist in allen Cloud-Plattformen mehr oder weniger ähnlich:
Zuerst gilt es, das interne Netzwerk zu definieren. Bei einem Zugangsrouter (bspw. ein Speedport) ist das typischerweise der interne Netzbereich mit IP-Adressen, die mit 192.168.x.x beginnen. In der Cloud wird dies Subnetz genannt. Ein Subnetz ist ein virtuelles Netzwerk, welches alle angeschlossenen Komponenten gemäß der IP-Adress-Logik verbindet. Dies ist vergleichbar mit den LAN-Buchsen am Speedport bzw. dessen WLAN, mit dem die Geräte intern verbunden werden.
Als nächstes gilt es, die benötigten Funktionen des Internetzugangs, die sich im Speedport befinden, in der Cloud virtuell nachzubauen. Diese sind:
- die interne Gateway-IP-Adresse, über die die Geräte ins Internet gelangen
- die öffentliche IP-Adresse, über die der Speedport aus dem Internet heraus ansprechbar ist
- die Network-Adress-Translation (NAT) – Funktionalität, d.h. Umsetzung mehrerer interner IP-Adressen im privaten Netz auf eine öffentliche IP-Adresse im öffentlichen Netz
- die Port-Weiterleitungs-Regeln; quasi eine „Einlasskontrolle“ für Datenpakte aus dem Internet in das interne Netz (es sollen nur die Datenpakete eingelassen werden, die für das Bereitstellen der Webseite notwendig sind)
Abschließend gilt es, den Computer zu modellieren. Dies geschieht in folgenden Schritten:
- Hardware (virtueller Computer), d.h. Prozessor, Arbeitsspeicher, Festplatte
- Betriebssystem einschließlich dessen Konfiguration (hierfür stellen Cloud-Plattformen vorkonfigurierte Module (Festplatten-Images) bereit)
- Anwendungssoftware (hier in dem Beispiel eine Web-Server-Software)
- Anwendung (hier in dem Beispiel die Web-Seite)
Final werden die drei Bereiche miteinander verbunden und in Betrieb genommen. Der ganze Vorgang ist unter einer ½ Stunde umsetzbar – und somit deutlich schneller realisierbar als ein physikalischer Aufbau.
Ich hoffe, dass ich Ihnen mit diesem kleinen Beispiel einen Eindruck von der praktischen Arbeit mit und der Effizienz einer Cloud-Plattform vermitteln konnte. Der Vollständigkeit halber wäre noch einzuräumen, dass in diesem Szenario aus didaktischen Gründen für die Schüler alle Schritte dieser Demo manuell und ohne Unterstützung durch Automatisierungssysteme vorgenommen wurden. Im praktischen Betrieb von großen und leistungsstarken IT-Plattformen und -Anwendungen wird dagegen genau umgekehrt verfahren. Hier sind alle Abläufe soweit wie möglich automatisiert und manuelle Tätigkeiten werden vermieden.
Besten Cloud-Speicher auswählen
Welche internationalen und deutschen Cloud-Lösungen gibt es?
Doch kommen wir zurück zu einer kompakten Betrachtung von verfügbaren Cloud-Plattformen. Da dies über den Rahmen dieses Beitrags deutlich hinausgeht, beschränken wir uns auf eine kurze Vorstellung der großen Cloud-Plattformen, in der Reihenfolge ihres chronologischen Markteintritts.
Große Cloud-Plattformen in chronologischer Reihenfolge ihres Markteintritts
- Amazon Web Services (AWS), seit 2006
Amazon Web Services (AWS) ist 2006 als Tochter des Online-Versandhändlers Amazon gegründet worden und war damit der erste große Anbieter von IT-Infrastrukturservices. AWS ist zwischenzeitlich einer der umsatzstärksten Cloud-Dienstleister. Viele bekannte Internet-Portale basieren auf Vorleistungen der AWS. - Microsoft Azure (Azure), seit 2010
Microsoft Azure (Azure) ist die seit 2010 verfügbare Cloud-Plattform von Microsoft, die sich in erster Linie an Softwareentwickler richtet. Microsoft bietet bezüglich der Anzahl der weltweit verfügbaren Regionen und (Verfügbarkeits-)Zonen eine sehr große Abdeckung. Ferner lassen sich in Unternehmen bestehende Microsoft-Umgebungen sehr gut mit den Azure-Diensten integrieren. - Google Cloud Platform (GCP), seit 2008
Mit der Google Cloud Plattform (GCP) bietet Google seit 2008 eine Reihe von Cloud-Computing-Diensten an, die auf der gleichen Infrastruktur laufen, die auch Google für seine Endbenutzerprodukte verwendet. Es werden Cloud-Dienste wie Computing, Datenspeicherung, Datenanalyse und Maschinelles Lernen angeboten. - Open Telekom Cloud (OTC), seit 2016
Die Open Telekom Cloud (OTC) ist 2016 als Infrastruktur-as-a-Service (IaaS) Angebot gestartet und zählt zu den deutschen Clouddiensten. Zwischenzeitlich sind darüber hinaus vielfältige Platform-as-a-Server (PaaS) und Software-as-a-Service (SaaS) Angebote verfügbar, die sukzessive ausgebaut werden. Die OTC basiert auf dem Software-Projekt Open Stack (Open Source, siehe unten), wodurch Softwarecode aus der Open-Stack-Community in der OTC verwendet werden kann. Die Open Telekom Cloud erfüllt die deutschen Anforderungen an Datensicherheit und Datenschutz, da die Leistungs-erbringung dem deutschen Recht unterliegt.
Open-Source-Cloud-Plattformen
Nachdem wir nun die großen Plattformen kommerzieller Anbieter betrachtet haben, werfen wir nochmal einen Blick auf Cloud-Plattformen auf Basis freier quelloffener Software (Open Source).
- Open Stack (OS), seit 2010
Open Stack (OS) ist ein 2010 gestartetes Softwareprojekt, welches eine freie Architektur für Cloud-Computing bereitstellt. Open Stack unterliegt der Apache-Lizenz, d.h. man darf Software unter dieser Lizenz u.a. frei in jedem Umfeld verwenden, modifizieren und verteilen.
Open Stack ist in der Programmiersprache Python geschrieben, die mit dem Ziel größter Einfachheit und Übersichtlichkeit entworfen wurde, wodurch sie und der Umgang mit Open Stack einfach zu erlernen ist. Nicht zuletzt durch den in Schulen und in der Ausbildung eingesetzten preiswerten und deshalb beliebten Mini-Computer RaspberryPi, der primär die Programmiersprache Python verwendet, beherrschen sehr viele junge Entwickler Python. Die Open Stack Foundation koordiniert die Entwicklung von Open Stack; ihr gehören mehr als 60.000 Mitglieder aus 180 Staaten an.
Die Cloud-Plattform ist das Fließband der Digitalen Revolution!
Wenn Sie diese Zeilen lesen freut es mich, dass Sie das Interesse und auch die Ausdauer hatten, sich ausführlicher über das Themenfeld Cloud-Computing zu Informieren. Ich hoffe, ich konnte Ihnen die Motivation für die Entstehung der Cloud-Technologie und deren Aufbau, Funktionsweise und Technolekt recht anschaulich erläutern. Des Weiteren Ihnen einen ersten Eindruck von der praktischen Arbeit mit einer Cloud-Konsole geben, einschließlich wie man hiermit für IKT-Problemstellungen effiziente Lösungen bauen und betreiben kann. Der Vollständigkeit halber gilt abschließend noch zu erwähnen, dass Cloud-Technologie deutlich mehr ist und leisten kann, als in diesen einleitenden Beitrag vorgestellt werden kann.
Henry Ford hat einst mit der Einführung des Fließbands die Verfügbarkeit von Automobilen in der Gesellschaft mit steigenden Quantitäten und Qualitäten und zu sinkenden Preisen in einer noch nie dagewesenen Art und Weise ermöglicht. Hierdurch wurden in nur 10 Jahren Pferdefuhrwerke aus dem Straßenbild von New York eliminiert. Das Fließband in der Epoche der „Digitalen Revolution“ ist die Cloud-Plattform; verpassen Sie das nicht!
Über den Autor: Dr. Jörg Benze
Dr. Jörg Benze ist Principal Consultant bei Telekom MMS und in den Bereichen Innovation, Business Development und Application Management & Cloud Services tätig. Seine Themenschwerpunkte sind hier neue Technologien, Architekturen sowie Geschäftsmodelle für die Digitalisierung im IoT- und Industrie-4.0-Umfeld.
Whitepaper DevOps und Cloud
Sie wollen die Basis effizienter Automatisierung schaffen? Laden Sie sich jetzt unser Whitepaper zum Thema „DevOps und Cloud – Synergieeffekte nutzen“ herunter und erfahren Sie, warum DevOps und Cloud mehr zusammenwachsen sollten und wie sich die Zukunft des IT-Betriebs im Hinblick auf Teamstrukturen, Skills, Rollen und Prozesse verändern müssen.
Zum Whitepaper